



















 The Latest 15 Information Technology Trends in 2024
The Latest 15 Information Technology Trends in 2024 Top 10 Embedded Software Development Tools
Top 10 Embedded Software Development Tools IaaS vs. PaaS vs. SaaS: What’s the Difference?
IaaS vs. PaaS vs. SaaS: What’s the Difference? 10 Examples of Predictive Analytics
10 Examples of Predictive AnalyticsThe CI/CD pipeline has become a popular practice among software developers as it automates the creation, testing and integration of applications. Infrastructure engineers were long in need of a similar practice for infrastructure automation, taking into account the growing complexity of IT systems at various enterprises. This is why the GitOps approach came into being.
In this article, I’ll explain to you the principles of GitOps, its connection to DevOps, the benefits of managing infrastructure using this approach, and how to put it into practice.
Request SaM Solutions’ DevOps services to automate and speed up your software’s deployment.
What Is GitOps?
GitOps is a relatively young approach in software engineering. It has emerged on the basis of DevOps best practices, such as continuous integration, continuous deployment, version control, collaboration, etc. The ultimate goal is to automate infrastructure updates, make the process traceable and avoid human error.
Definition: GitOps is a set of practices/an approach to a modern implementation of continuous deployment for cloud-native applications. When we talk about GitOps, we mean not only the deployment of the application source code, but also the deployment of infrastructure using tools that are popular among developers — Git, IaC (Infrastructure as Сode), continuous integration.
The essence: you describe the infrastructure you need for the target environment in a declarative manner and store the descriptions in a special Git repository; the process of making the environment match the described state is automated.
In a nutshell, developers are empowered to perform tasks that were traditionally performed by the Ops. If they want to deploy a new application or update an existing one, they only need to update the repository, and an automated process handles everything else.
The most popular declarative cloud infrastructure today is Kubernetes. GitOps is a perfect operating model for the Kubernetes-based infrastructure and applications development and delivery, as it combines Git with the Kubernetes convergence properties.
It All Starts with Infrastructure as Code (IaC)
For a better understanding of GitOps, we should first explain the Infrastructure as Code (IaC) concept.
Previously, operations engineers had to create infrastructure manually using PowerShell and kubectl scripts. In recent years, the practice of defining infrastructure (as well as configuration, network, security and other components) in code is gaining traction.
Instead of creating a Kubernetes cluster with multiple nodes, you describe everything you need in files, using tools such as Terraform, Ansible, YAML Kubernetes manifest files, etc. This allows you to simplify the reproduction and replication of infrastructure and its components.

There are two options for making it work:
- A DevOps engineer creates, tests, executes and stores all files locally on the computer.
- A DevOps engineer creates a Git repository for IaC and stores all these files on Git. This is the preferable option because you get version control for your files, and other team members have access to the code.
However, this second method has serious disadvantages:
- No pull requests. If you or your team members change the code, it is directly committed to the main branch.
- No code review. Consequently, nobody can collaborate on the changes and review the code.
- No automated testing. If you’ve committed files with errors, you’ll only find out once you applied them to the environment, because no automated tests are running to check the changes.
- No traceability. Each team member tests their changes manually in the development environment and then applies the changes manually in the staging and production environment. They access the Kubernetes cluster or cloud-platform infrastructure from the local computer and execute Terraform or Ansible commands. Hence, it’s hard to trace the history of changes and find out who applied a particular feature, which is critical if errors are found.
As you can see, IaC is a convenient method of infrastructure management, though it still needs improvements. This is where the GitOps concept comes into play. It aims to ensure the treatment of Infrastructure as Code in the same way as the application code, i.e. by combining a Git repository with a full DevOps pipeline (CI/CD).
How Is GitOps Different from DevOps?
Looking at their names, it’s obvious that the two are interconnected. The definition from Wikipedia says that DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) with the aim to shorten the systems development life cycle and provide continuous delivery with high software quality.
GitOps is a logical continuation of the ideas that were incorporated in DevOps. In particular, GitOps is the evolution of the Infrastructure as Code concept, which itself originated in the DevOps environment.
GitOps has bridged the gap between existing DevOps practices, which were designed to address system administration challenges, and the specific needs of distributed cloud-hosted applications.
As a separate practice, GitOps may be included in a set of DevOps practices; precisely, it aims at closer interaction with developers. Since Git is already being used for software development, engaging Git in operations not only involves DevOps techniques but also harnesses the power of version control.
How GitOps Works
As mentioned, the workflow of GitOps is based on the integration of the IaC system and the CI/CD pipeline. Let’s look at the GitOps operating mechanism.

1. First, a separate Git repository for the IaC project is created.
2. If you need to make changes to the code, you create a pull request.
3. A CI pipeline ensures the validation of config files and runs automated tests.
4. After automated testing, any team member can review commits and approve the pull request.
5. Finally, approved updates are merged into the main branch through a CD pipeline and are then deployed to the Kubernetes environment. In other words, this is where new versioned artifacts of the infrastructure are prepared.
Thus, infrastructure code changes go through the same stages as application code changes. As a result, all changes are reviewed and tested before being applied in any environment, which significantly reduces the risk of breaking something.
6. The convergence mechanism ensures that updates made in the repository are applied to the Kubernetes cluster: the Kubernetes orchestrator compares properties of the cluster with updates in Git and applies them to the cluster until the observed state is identical to the configuration files in the repository. This mechanism is applicable to any Kubernetes resource.
GitOps Principles
1. Declarative description of systems. The definition and configuration of systems are described as source code (e.g., YAML Kubernetes manifests). The code is stored and automatically versioned in a Git repository, which serves as the only source of truth. This approach makes it easy to roll out and roll back system changes.
2. Setting and versioning of the system’s desired state and configuration in Git. By storing and versioning the desired state of systems in Git, you have the ability to easily roll out and roll back changes in systems and applications. You can also use Git’s security mechanisms to control ownership of the code and verify its authenticity.
3. Automatic application of approved changes. Using Git pull requests, you can easily control how changes are applied to configurations in the repository. For example, you can give them to other team members for verification or run through CI tests, etc. To commit configuration changes, users only need the appropriate permissions in the Git repository where these configurations are stored.
4. Eliminating the problem of uncontrolled drift of configurations. When the desired state of the system is stored in the Git repository, you only need to add software that would control that the current state of the system corresponds to its desired state. If there are inconsistencies, the software should either fix them or warn about the drift of configurations.
How Is GitOps Put into Practice?
In systems working with GitOps, there is usually:
- a separate Git repository for infrastructure
- a separate Git repository for the application code
- the CI/CD pipeline.
The infrastructure repository is the only place in the system where the infrastructure configuration code is stored. This code manages configuration, creation, updating, and possibly deletion. This repository is the heart of IaC and the source of truth about what the infrastructure should be and what should work in it. When they want to make updates, developers upload files with code that acts as deployment instructions to this repository.
If the state of the infrastructure differs from the state described in the repository, GitOps, as a tool, must bring the target state of the system to the state described in the repository.
The application code repository is the basic project code.
The third component of the system, the CI/CD pipeline, should be somehow connected with repositories to know when to run tests and deploy.
For this purpose, there are two deployment strategies in GitOps.
1. Push-Based Deployments
A push-based deployment strategy is essentially a classic CI/CD implementation using tools such as Azure DevOps, GitHub Actions, Jenkins, GitLab, and so on.
We can see how it works by looking at Sitecore as an example. We have the source code of our Sitecore instance in the Git repository. In the same repository, we also store Kubernetes YAML files (infrastructure) necessary for deploying the application. As soon as the application code changes (Git Push), a pipeline build is triggered. It builds the container images, pushes these images to the Container Registry and deploys updated Kubernetes infrastructure manifests.
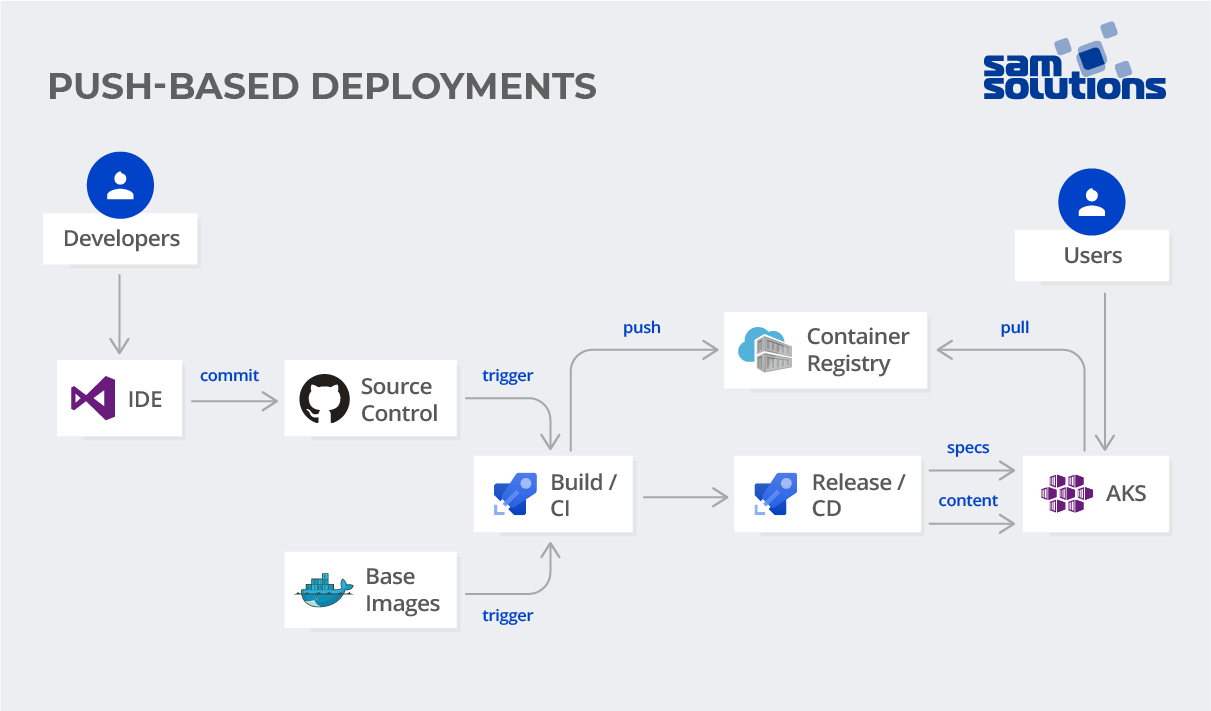
Note: There is a certain practice whereby the infrastructure code (YAMLs) is placed in a separate environment repository (see the scheme below). This approach is a little more complicated since it’s necessary to implement the update of the environment repository during the build of the pipeline.

Using the Push approach has some pros and cons.
Pros
- The Git repository and assembly pipeline define security.
- Secret management is easier because secrets can be used in pipelines and stored in Git using encryption.
- You’re not tied to a specific tool — you can use any type.
- Container version updates can be initiated by the assembly pipeline.
Cons
- Data for accessing the cluster is stored in the assembly system.
- Updating the deployment containers is still easier in the pull process.
- High dependency on the CD system (pipelines are written for a specific tool, and if the team decides to use another tool, they will have to migrate numerous pipelines).
- The degree of security is still lower than in the pull process.
- More monitoring is required.
2. Pull-Based Deployments

With a pull-based approach, the same concepts are used as with the push-based approach. The difference is that an operator is added to perform the role of a pipeline.
An operator (agent) is installed in the environment (e.g., Kubernetes cluster) and pulls changes from the repository itself. The operator regularly checks the state of the infrastructure code in the repository, comparing it to the current state in the environment. If a difference in the repository is detected, the agent pulls and applies changes in the environment to get it from the actual to the desired state. Moreover, it monitors the image registry for any new versions of images.
Unlike a push-based process that updates the environment only when the repository is updated, a pull-based deployment can find changes even if they aren’t described in the repository. An operator will send you a notification if it can’t apply the requested changes to the environment. This means there is a greater degree of transparency.
Tools working with the pull-based model are Flux and Argo. They run inside the Kubernetes cluster and transfer updates from the repository to the cluster. The Kubernetes API server accepts declarative descriptions of updates and manipulates the objects in the cluster (e.g., namespaces, pods, events, ConfigMaps) in order to achieve the desired state as described in the Git.
Pros
- Nobody can change the cluster from the outside.
- You can scan Docker Registry for new versions and, if found, update the repository and deployment.
- Pull tools can be distributed across various namespaces with different Git repositories and access rights. This makes it possible to use a multi-tenant model.
- Secrets can be stored encrypted in Git and extracted inside the cluster.
- There is no dependency on the CD pipeline because deployments take place inside the cluster.
Cons
- It’s more difficult to manage deployment secrets from Helm charts.
- You are tied to pull operating tools, which limits configuration opportunities in the cluster.
Benefits of Using GitOps

- Automation — when configuring infrastructure, manual tasks are eliminated, saving a lot of time.
- Transparency — the process allows you to easily trace all the changes made to the code due to time stamps, commit IDs and all the information about committers.
- Collaboration — since everyone in the team can collaborate on the code and review updates, the result is always of high quality.
- Fast and frequent deliveries — teams can deliver updates faster and more frequently due to the automation process; it may take from several hours to several minutes.
- Easy rollback — due to version control, you can easily roll back your environment to any previous state; this is highly important if applied changes break something and the cluster doesn’t work.
- Security — the code review opportunity, automated testing and version control make deployment more secure.
- Self-documenting deployment — there is no need for architects or tech leads to keep the infrastructure documentation separately: everything is stored in Git, so there is always an up-to-date version. In addition, this approach enables fast onboarding of new developers to the project.
GitOps Challenges
The greatest challenge is the initial configuration of the process. As soon as everything is set up, the system will run like clockwork.
You may face another issue — the engagement of all team members in this process. Working with GitOps may seem boring and time-consuming to those developers who are used to making quick changes manually. That’s why you should take time to explain GitOps benefits and convince your teammates to follow the new process and write down every change diligently.
GitOps Example
The following is an example of using GitOps from my practical experience.
In one Sitecore project, the client identified a performance issue in the live site (content delivery, using Sitecore terminology). The Dev team looked into the GitOps repository that held infrastructure configuration and figured out all major Sitecore deployments (CM, CD, Identity) configured (via nodeSelector settings) to run pods on the same Kubernetes Node at a time when the cluster had another empty Node.
The Dev team decided to rebalance the pods to run CD separately from CM and Identity.
- A developer opened up a new pull request to apply appropriate nodeSelector settings to the CD YAML configuration.
- That pull request was reviewed and approved by the Dev team and merged into the repository.
- The merge kicked off a GitOps pipeline, which triggered the GitOps operator (Pull strategy).
- The operator detected that the CD configuration had changed. It confirmed with the systems orchestration tool that this did not match what was live on the cluster.
- The operator alerted the orchestration system to update the CD configuration.
- The orchestrator handled the rest and automatically deployed the newly configured CD.
- The Dev team confirmed that the CD pod was running on another Node and the performance issue was gone.
Conclusion
GitOps is an incredibly powerful automated operating model for managing modern cloud-native solutions and infrastructure. Unlike the IaC concept that deals with disintegrated local machines, GitOps ensures centralized storage of files on a remote server backed up by DevOps best practices.
Though initially focused on Kubernetes cluster management, GitOps can be applicable to other non-Kubernetes systems, bringing numerous benefits to them. If you need to improve the communication in your team, ensure the transparency and reliability of the system, I highly recommend you consider GitOps for infrastructure management.

Vadzim Papko is a Sitecore MVP, Sitecore Architect and Chief .NET Technologist at SaM Solutions. Adhering to the principles of non-stop self-development, he devotes himself to Sitecore innovation and popularization. Follow him on Twitter @VadzimPapko and subscribe to his Telegram channel Amazing Sitecore @amazingsitecore
![Web App Development Cost in 2025 [Key Price Factors]](https://www.sam-solutions.com/blog/wp-content/uploads/fly-images/31797/Web-App-Development-Cost-cover@2x-370x238.webp)











 Web App Development Cost in 2025 [Key Price Factors]
Web App Development Cost in 2025 [Key Price Factors] 13 Best React Development Tools in 2025
13 Best React Development Tools in 2025 Top 10 Mobile App Development Trends 2025
Top 10 Mobile App Development Trends 2025 Top IoT Industry Trends in 2025
Top IoT Industry Trends in 2025 Java Web App Security: Everything You Need to Know
Java Web App Security: Everything You Need to Know