LLM Fine-Tuning Architecture: Methods, Best Practices and Challenges


(If you prefer video content, please watch the concise video summary of this article below)
Key Facts
- Definition: LLM fine-tuning adapts a pre-trained large language model to a specific domain or task using targeted data — turning a general model into a specialized expert.
- Efficiency: Requires only thousands of examples and a short training period — often up to 90% faster and cheaper than building a new model from scratch.
- Main approaches: Full fine-tuning (updates all weights) and parameter-efficient fine-tuning (LoRA, QLoRA, adapters, prefix tuning).
- Advanced methods: Flash Attention for speed, Mixture-of-Experts for specialization, and improved layer normalization for stability.
- Challenges: Overfitting, bias in small datasets, and high compute costs for large models.
- Business value: SaM Solutions delivers secure, cost-efficient fine-tuning of LLMs tailored to enterprise needs and compliance requirements.
Building a new AI model from scratch can be very costly in data and time. Instead, one of the top trends of 2025 is to fine-tune an LLM. This way, a general model can become, say, an expert customer service agent or a legal advisor by learning from domain examples.
It’s highly efficient: you might need only a few thousand targeted examples and a short period of training, versus millions of examples and weeks for training from zero. This is one of the top trends of recent years, with more businesses embracing fine-tuning as a quick path to AI solutions focused on their unique needs.
What Is LLM Fine-Tuning?
LLM fine-tuning architecture means taking a large language model that’s already broadly trained and training it a bit more on new, focused data to specialize it. For example, you can fine-tune a general model on your customer support transcripts so it learns to answer questions in your company’s style and context. The process doesn’t start from scratch; it nudges the model’s existing knowledge (like giving it on-the-job training) so the model keeps its broad language skills but becomes much better at your specific task or domain.

Key Fine-Tuning Approaches
Broadly, there are two ways to fine-tune a model: update all of its parameters (full fine-tuning) or update only some of them (parameter-efficient fine-tuning).
Full fine-tuning
In full fine-tuning LLM architecture, you update all the weights of the model on your new task data. This gives the model maximum flexibility to adapt and often yields the best performance. However, it requires significant computing power and can sometimes cause the model to overfit or “forget” some of its prior knowledge. Full fine-tuning is best when you have a large enough dataset and ample resources.
Parameter-efficient fine-tuning (PEFT)
Parameter-efficient fine-tuning updates only a small fraction of the model’s parameters, keeping most of the model frozen. This greatly reduces memory and compute needs with minimal impact on performance. Instead of adjusting every weight, PEFT methods add a tiny set of new trainable parameters to the model. Common methods include:
- LoRA (low-rank adaptation): adds small trainable weight matrices to each layer; only these new weights are learned.
- Adapter modules: inserts small adapter layers between existing model layers; only adapter weights get trained.
- Prefix tuning: prepends a set of learnable “prefix” tokens to the input; only these token embeddings are trained.
QLoRA (Quantized LoRA)
QLoRA combines LoRA with model quantization (using lower-precision numbers for the model’s parameters). It loads the LLM in a compact 4-bit mode and then applies LoRA fine-tuning on top. Because the model is much smaller in memory when quantized, QLoRA lets you fine-tune very large models on a single GPU without much loss in performance. In 2025, QLoRA is widely used as a cost-effective way to fine-tune top-tier models on modest hardware.

Advanced Techniques in Fine-Tuning
As fine-tuning becomes more common, there are top 3 advanced techniques that are used in 2025 to improve speed or effectiveness beyond the basics.
Leverage AI to transform your business with custom solutions from SaM Solutions’ expert developers.
Task-Specific Fine-Tuning Strategies
Fine-tuning can be tailored to specific goals or use cases:
Instruction tuning involves fine-tuning a model on examples of instructions paired with ideal responses. This teaches the model to better follow human instructions. It’s how models like GPT-3 were adapted into instruction-following versions (the technique behind making ChatGPT behave helpfully). If your AI will interact with users and follow prompts, instruction tuning helps it respond correctly and politely to a wide range of requests.
Domain adaptation fine-tuning focuses the model on a specific field or industry. For example, taking a general LLM and training it on medical literature will yield a model much better at answering medical questions. The fine-tuned model learns the jargon, facts, and style of that domain. This approach ensures your AI’s knowledge and tone are appropriate for the domain (finance, law, medicine, etc.) in which it will be used.
Multi-task learning means fine-tuning the model on multiple tasks at once instead of just one. For instance, you could combine data for translation, summarization, and question-answering and train a single model on all of it. The model learns to handle different types of prompts and can become more versatile. In some cases, training on related tasks can even improve overall performance because the model picks up general skills that transfer across tasks. The challenge is to balance the tasks so one doesn’t dominate the training process.
Hyperparameter Optimization
Choosing the right training settings (hyperparameters) is crucial for a successful fine-tune.
Learning rate scheduling
Using an appropriate learning rate (and schedule to adjust it) is very important in fine-tuning. Typically, you use a small learning rate, often with a short warm-up phase (gradually ramping up from a very low rate) and then a slow decay. Fine-tuning generally needs a much lower learning rate than training from scratch, since the model’s weights only require gentle adjustments. A proper learning rate schedule helps keep training stable and avoids overshooting the optimal weights.
Batch size considerations
Batch size – the number of examples processed in one training step – affects training speed and stability. Larger batches can make gradient updates more stable and make efficient use of hardware, but they demand more memory. With LLM fine-tuning, batch sizes are often limited by GPU memory (sometimes only 8 or 16 examples per batch). Techniques like gradient accumulation can simulate a larger batch by accumulating gradients over several steps before updating the weights. The goal is to use the largest batch size your hardware can handle without running out of memory or harming generalization.
Early stopping mechanisms
Early stopping means halting training when further improvement stops, to prevent overfitting. In fine-tuning, it’s common that after a few passes through the data, the model’s performance on a validation set plateaus or even worsens. By monitoring a metric like validation loss or accuracy and stopping when it hasn’t improved for a preset interval, you capture the best version of the model. Early stopping ensures you don’t waste time and that the model doesn’t start overfitting the training data.

Popular Models for Fine-Tuning
Pre-trained LLMs that can be fine-tuned generally fall into three categories: encoder-only, decoder-only, and encoder-decoder (hybrid) LLMs.



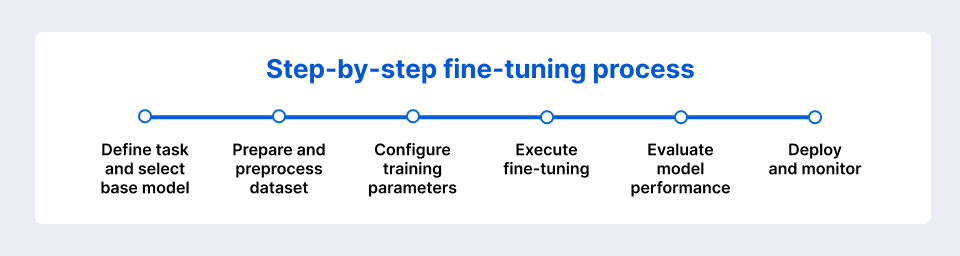
Step-by-Step Fine-Tuning Process
When you’re ready to fine-tune an LLM, the process generally looks like this:
Identify the specific task and pick a suitable pre-trained model. For example, use an encoder like BERT for classifying text or a decoder like GPT-3 for a chatbot. Consider the model’s language coverage, size (larger models may perform better but require more resources), and license (open-source vs. proprietary).
Collect and clean your task data, removing noise or sensitive information. Format it consistently (for instance, pairs of “question → answer” for a Q&A task) and tokenize the text using the model’s tokenizer. Finally, split your data into a training set for the model to learn from and a validation set to evaluate progress.
Set the hyperparameters for training. Choose a very low learning rate (fine-tuning often uses around 1e-5), decide on a batch size that your hardware can handle, and set the number of training epochs or steps (usually only a few). Select an optimizer (AdamW is common) and configure any special settings like a learning rate schedule or a method like LoRA if you’re using one.
Run the fine-tuning job on your hardware or a cloud platform. As the model trains, monitor the process – you should see the training loss decreasing and the validation performance improving. If the model isn’t learning (e.g., the loss isn’t dropping at all), you might pause and adjust settings (like reducing the learning rate). Fine-tuning could take minutes to hours depending on the model and data, so keep an eye on it to ensure everything stays on track.
After training, evaluate the model on your validation or test set to see how well it generalizes. Check the key metrics for your task and also review some outputs manually to make sure they meet your needs (for example, are the answers correct and well phrased?). This evaluation shows whether the fine-tuned model is ready for deployment or if further tuning and data are needed.
Deploy the fine-tuned model in your application (for example, as a service behind an API or as part of a software product) and monitor its performance over time. Track how quickly it responds and whether the outputs remain accurate and appropriate as new data comes in. User feedback is valuable here – it can highlight issues that weren’t obvious in testing. Using this monitoring, you can decide when to update the model or fine-tune it again with new data to keep it performing well.
Challenges in LLM Fine-Tuning
Fine-tuning is powerful, but it comes with some challenges to keep in mind:
Overfitting and catastrophic forgetting
If your fine-tuning dataset is very small or narrow, the model can overfit – performing well on that specific data but poorly on new, unseen inputs. There’s also the risk of catastrophic forgetting, where a model becomes so specialized on the new data that it loses some of the general knowledge it had before. For instance, an LLM fine-tuned solely on legal documents might struggle with everyday topics because it “forgot” non-legal information. To avoid these issues, use a low learning rate and limit the number of epochs, and consider mixing in some general data or using techniques like early stopping to retain the model’s original versatility.
Computational costs
Fine-tuning large LLMs can be expensive in terms of computation. They have billions of parameters, so training them requires strong hardware (GPUs or TPUs with a lot of memory) and possibly distributed computing across multiple devices. If you’re using a cloud service, the costs can add up with long training times. Techniques like PEFT and QLoRA can significantly cut down the required compute by reducing how many parameters need updating or by compressing the model. Still, it’s important to plan your budget and resources – sometimes using a slightly smaller model or a more efficient method is a smart trade-off to ensure the project is feasible.
Bias amplification
LLMs can also amplify biases present in the fine-tuning data. If the dataset is skewed or contains prejudiced or one-sided content, the model’s outputs may reflect those biases or inappropriate tones. To mitigate this, it’s crucial to review and balance your training data and to test the model’s outputs for fairness and accuracy. You might also fine-tune on additional “safe” or more diverse data, or apply filters to the model’s outputs to ensure the AI’s responses meet ethical standards and won’t offend or discriminate. Being mindful of bias isn’t just about avoiding bad press – it can be important for complying with regulations and for building AI that users trust.






Cloud Platforms for Fine-Tuning
Let’s explore the top 3 cloud platforms for fine-tuning in 2025:



Future Trends in LLM Fine-Tuning
Fine-tuning is becoming more automated and more versatile. AutoML tools are emerging to help find optimal fine-tuning settings without as much human trial-and-error. Models are also getting more multimodal – future fine-tuning might involve LLMs that understand not just text but also images, audio, and beyond. Privacy-aware fine-tuning is gaining importance too, with techniques to train models without centralizing sensitive data (to adhere to privacy laws and protect user data). Finally, efficiency will continue to improve – expect faster training and smaller, cheaper models to deploy.
Ready to implement AI into your digital strategy? Let SaM Solutions guide your journey.
Why Choose SaM Solutions For AI Development?
At SaM Solutions, we offer one of the best price-quality ratios on the market, making advanced AI development both effective and cost-efficient. Our team combines deep expertise in LLM fine-tuning with a strong commitment to data protection and regulatory compliance. From secure data handling to tailored model training and deployment, we prioritize the confidentiality and integrity of your information at every step.
Conclusion
LLM fine-tuning is an efficient way to adapt big pre-trained LLMs to your specific needs, rather than building them from scratch. It’s a shortcut to high performance on specialized tasks. We discussed approaches from full fine-tuning to LoRA and highlighted best practices to avoid pitfalls like overfitting or bias. With the right approach, fine-tuning can produce remarkable results. As AI technology advances, fine-tuning will remain essential to keep LLMs aligned with your domain, goals, and values.
FAQ
Fine-tuning open-source LLMs means you have full access to the model’s weights and complete control over the training process and final model. With proprietary LLMs (closed-source models offered via an API), you typically cannot directly access or modify the model’s weights. Fine-tuning, if available, happens through the provider’s service under their constraints. In short, open-source LLMs give you flexibility and ownership, while proprietary ones give you convenience but keep you dependent on the provider’s platform.






![15 Best AI Tools for Java Developers in 2026 [with Internal Survey Results]](https://sam-solutions.com/wp-content/uploads/fly-images/18712/title@2x-6-366x235-c.webp)






