What Is Multi-Token Prediction (MTP): Complete Guide


(If you prefer video content, please watch the concise video summary of this article below)
Key Facts
- Multi-token prediction helps LLMs move beyond the slow one-token-at-a-time process by predicting several future tokens in parallel.
- MTP can improve inference speed, throughput, and cloud cost efficiency through stronger hardware utilization and acceleration.
- The approach is especially valuable for coding assistants, enterprise chatbots, real-time apps, and edge AI systems.
Artificial intelligence systems use different approaches to generate content, depending on the task. Some models produce text sequentially through autoregressive prediction. Others use diffusion to create images or videos. Retrieval-augmented models combine generation with external knowledge sources in real time.
Still, most modern large language models (LLMs), including GPT-style architectures, Llama, and Claude, have relied on one core principle: next-token prediction. The model generates text one token at a time, predicting the most probable next piece of a sentence. The term “next-token prediction” can sound misleading. Modern transformers do not ignore the broader context. Through the attention mechanism, the model analyzes the entire available sequence before generating each new token. The limitation lies elsewhere: despite understanding long contexts, the model still produces output sequentially.
Now, some of the biggest players in AI are attempting to change that paradigm. Instead of predicting only the next token, researchers are exploring multi-token prediction (MTP), where models attempt to generate several future tokens simultaneously. The goal is straightforward: make large-scale AI systems faster and more efficient.
The idea sounds simple. The implementation is not. Predicting multiple future tokens creates new technical challenges. Let’s discuss.
What Does Multi-Token Prediction Mean in AI?
If traditional artificial intelligence is a solo pianist reading one note at a time, multi-token prediction (MTP) is a jazz quartet that knows exactly where the melody is going three bars before they get there. It is a fundamental divorce from the one-at-a-time autoregressive bottleneck.With next-token prediction, the AI model calculates logits — raw scores that are later converted into probabilities — for token n+1. Simple. Linear. Slow. MTP flips the script by tasking the model’s internal architecture with producing logits for several future positions at once, such as n+1 through n+4. Instead of asking, “What is the next word?”, the model starts asking, “What short sequence is most likely to come next?”
But speed does not mean blind acceptance. These predicted tokens are treated as a draft: the model verifies them, accepts the sequence if it is likely enough, or rolls it back when the prediction fails.
As of now, the real-world result still depends heavily on the model itself — its architecture, training quality, reasoning ability, and how accurately it can predict and validate future tokens. That verification layer is what keeps MTP from becoming reckless speculation. It allows artificial intelligence to move faster while still protecting the quality and reliability of the generated output.
How Multi-Token Prediction Works
Multi-token prediction is a training and inference technique that helps language models look several tokens ahead instead of focusing only on the next single token.
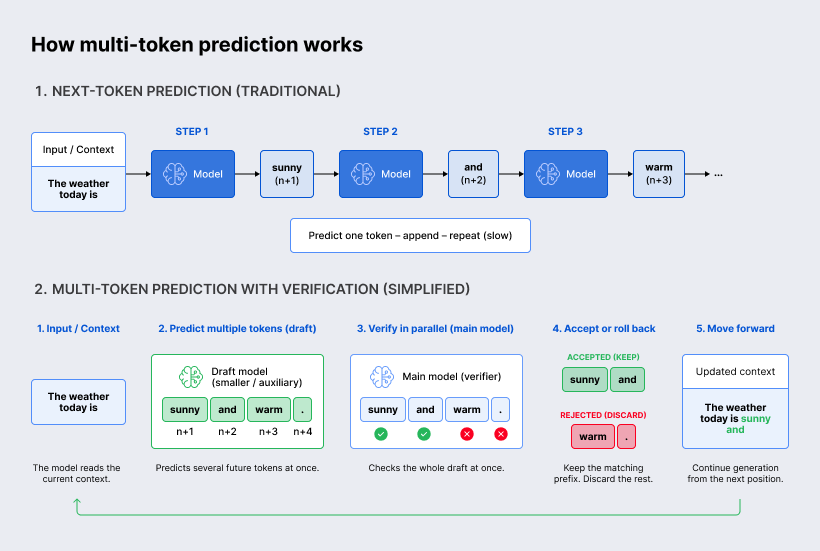
In a standard language model, generation works like this:
- Given the text so far, predict token n+1.
- Then use that result to predict token n+2.
- Then repeat.
This is called next-token prediction, and it is the basic mechanism behind most autoregressive LLMs. It is reliable, but slow, because the model has to move step by step through the sequence.
Recent research on multi-token prediction proposes a broader objective: at each position, the model predicts several future tokens at once using multiple output heads on top of a shared model trunk.
- For example, if the context is: “Actions speak louder than”
- A traditional model predicts only the next token: “words”
- A multi-token prediction system may try to predict a short continuation: “words .”
- or even: “words in practice”
The key point is that MTP does not blindly print all predicted tokens. The extra tokens are usually treated as a draft.
During faster inference, this is often combined with speculative decoding. A smaller or auxiliary “drafter” predicts several possible future tokens. Then the main model verifies these suggested tokens in parallel. If the main model agrees, the whole draft can be accepted in one step. If it disagrees, the incorrect part is rejected and generation continues from the corrected point. Google describes this as separating token generation from verification: the drafter proposes future tokens, while the target model checks them.
So the process looks like this:
- Context is processed. The model reads the existing prompt and builds an internal representation.
- Several future tokens are proposed. Instead of predicting only token n+1, the MTP heads or drafter propose n+1, n+2, n+3, and so on.
- The draft is verified. The larger target model checks whether these proposed tokens match what it would have produced.
- Accepted tokens move forward. If the prediction is good, multiple tokens are added at once.
- Wrong predictions are rolled back. If the verifier rejects part of the draft, the system keeps only the valid prefix and discards the rest. This preserves output quality while still allowing speedups when the draft is accurate. Speculative decoding was introduced specifically to compute several tokens in parallel without changing the target model’s output distribution.
The advantage is speed. Standard inference is often limited by memory bandwidth: the system repeatedly loads huge model weights just to generate one token at a time. With MTP-style drafting, the model can make better use of available compute by checking several candidate tokens in one pass.
Google reports that MTP drafters for Gemma 4 can provide up to a 3x inference speedup without degrading output quality, because the main model still performs the final verification.
In simple terms:
- Next-token prediction asks: “What is the next word?”
- Multi-token prediction asks: “What short sequence is likely to come next — and can the main model approve it?”
That verification step is crucial. Multi-token prediction is not just faster guessing. It is controlled guessing: the system speculates, checks the draft, accepts what is valid, and rolls back what is not.
Multi-Token Prediction vs. Next-Token Prediction
If we look under the hood, the transition from Next-Token Prediction (NTP) to Multi-Token Prediction (MTP) is less of a minor tune-up and more of a complete engine swap.
Core technical difference
Standard next-token prediction is strictly linear. The model is a perfectionist focused entirely on the immediate horizon; it calculates a probability distribution for a single point in time (n+1). Once that token is chosen, the entire context window shifts, and the process starts from scratch.
MTP, however, is spatial. It treats the future as a multi-dimensional probability landscape. By predicting a span of tokens (n+1 through n+k) in a single computational heartbeat, it breaks the dependency on that one-step-at-a-time loop. It’s the difference between reading a sentence through a straw and seeing the whole paragraph at once.
Impact on model training
In the NTP world, the training signal is relatively thin. The model only gets feedback on its ability to guess the very next character. This often leads to models that are great at grammar but shaky on long-term planning, they can start a sentence beautifully and end it in a logical train wreck.
MTP training is like a weighted education. Because the loss function evaluates multiple future tokens at once, the model is forced to develop a much higher degree of contextual foresight. It learns that every choice it makes has ripple effects four or five steps down the line. This produces a much denser supervision signal, meaning the model extracts more intelligence from every byte of training data.
Impact on inference speed
This is where the business value hits the road. In traditional inference, the GPU is waiting for data to move — a bottleneck known as memory bandwidth. Even if you have the fastest chip in the world, predicting tokens one by one is like trying to empty a swimming pool with a teaspoon.
MTP allows the model to propose a draft of several words and verify them in a single batch. If the guesses are correct (which they often are for common phrases or structured code) the model can output 3 or 4 tokens in the time it used to take to produce one. It’s a massive win for throughput. It’s the difference between making four trips to the grocery store for four items, or just grabbing the whole bag in one go.
| Feature | Next-token prediction (NTP) | Multi-token prediction (MTP) |
|---|---|---|
| Philosophy | Linear and autoregressive | Parallel and spatial |
| Output goal | Single most likely next token (n+1) | A chunk or sequence of tokens (n+1…n+k) |
| Learning signal | Low-density (One error signal per step) | High-density (Multiple error signals per step) |
| Logic/Reasoning | Local (Focus on immediate fluency) | Global (Focus on structural coherence) |
| Inference path | Sequential (Token-by-token) | Speculative (Multi-token verification) |
| GPU efficiency | Memory-bandwidth limited | Optimized via parallel batching |
Why Multi-Token Prediction Is Important for LLMs
MTP doesn’t just shave a few milliseconds off your chat response; it’s a fundamental survival strategy for an era where high-quality data is rare and the memory wall is real. It solves the three biggest headaches in modern AI development.
Better sample efficiency
In the world of next-token prediction, training is a slow burn. An LLM model learns one fact per token, the identity of the next word.
Multi-token prediction effectively densifies the training signal. When a model like DeepSeek-V3 or Gemma 4 is trained with MTP, it receives multiple streams of feedback for every single input. It isn’t just learning that “The cat sat on the…” is followed by “mat”; it’s simultaneously learning the grammatical structure of the next four words. This high-density learning allows models to achieve higher intelligence levels with significantly less training data. For enterprises working with specialized, smaller datasets, MTP is the key to getting big model reasoning out of a leaner training run.
Faster text generation
The most visible impact of MTP is the sheer velocity of the output. By the middle of 2026, we’ve seen inference speeds explode. For instance, the latest implementations of DeepSeek V3.2 on Blackwell architecture are clocking in at over 230 tokens per second.
This happens because MTP is a perfect foundation for speculative decoding. Instead of a secondary draft model doing the work, the MTP heads provide high-quality guesses that the main model verifies in parallel. If the predictions are right, the model effectively skips ahead.
If the prediction is wrong, however, the system does not blindly continue. The verifier keeps only the correct part of the draft, rejects the first mismatched token and everything after it, and rolls generation back to the last reliable position. From there, the main model resumes normal decoding or creates a new draft. In other words, MTP can accelerate generation when its guesses are accurate, but verification prevents incorrect continuations from contaminating the final output.
Here is a useful Gemma 4-specific comparison. The clearest benchmark is from JarvisLabs, which tested Gemma 4 31B Dense and Gemma 4 26B-A4B MoE on a single H100 80GB GPU with vLLM, comparing baseline decoding, Google’s MTP speculative decoding, and DFlash (an advanced AI framework for accelerating LLM inference) speculative decoding.
| Dense vs. MoE speedup comparison for Gemma 4 | ||||
| Model | Baseline | MTP | DFlash | Main result |
| Gemma 4 31B Dense | 40.3 tok/s | 125.3 tok/s | 122.1 tok/s | MTP wins, about 3.11x faster |
| Gemma 4 26B-A4B MoE | 177.1 tok/s | 264.2 tok/s | 306.4 tok/s | DFlash wins, while MTP gives about 1.49x speedup |
For Gemma 4, tests show that multi-token prediction accelerates generation more strongly on dense models than on MoE (Mixture of Experts) models. In one H100 benchmark, Gemma 4 31B Dense improved from 40.3 to 125.3 tokens per second with MTP — a 3.11x speedup. Gemma 4 26B-A4B MoE also became faster, rising from 177.1 to 264.2 tokens per second, but the gain was smaller because the MoE model already activates only a small subset of parameters per token. In other words, dense models have more decoding cost to save, while MoE models start from a faster baseline and face additional expert-routing overhead during verification.
Improved long-range context learning
Standard LLMs often suffer from local bias. They are so focused on the next syllable that they lose the structural thread of the whole paragraph. They’re like hikers who never look up from their boots.
MTP forces the model to look at the horizon. Because it’s graded on its ability to see several steps ahead, it develops a primitive form of forethought. It stops making silly mistakes, like dropping a closing bracket in code or losing a variable in a math proof, because it has already mapped out the logical landing zone before it even starts typing.
Multi-Token Prediction and Speculative Decoding
If MTP is the planning phase, Speculative Decoding is the execution. By 2026, the two have essentially merged into a single, high-speed workflow that has finally broken the back of the LLM latency problem.
How draft outputs are generated
In the early days of speculative decoding, you needed two separate models: a small, “dumb” one to make quick guesses and a large, “smart” one to check the work. It was effective but clunky. MTP changes the game by making the model its own drafting partner. Those auxiliary heads we discussed earlier act as a built-in fast-track, spitting out a string of 1 to 4 speculative tokens alongside the primary one. No second model required.
How verification works
Once the MTP heads have thrown their guesses onto the table, the main trunk of the model performs a single, decisive forward pass. It’s a trust but verify system. The model looks at the whole proposed block of text and asks: “Do these tokens align with my full probability distribution?” If the first three guesses are solid but the fourth is a hallucination, the model accepts the first three, discards the rest, and starts the next draft from that point.
Why it can reduce latency
Why does this matter? Because in modern AI, the bottleneck isn’t the math but the “commute.” Every time a GPU generates a token, it has to fetch massive weight files from memory. This is the Memory Wall.
By using MTP for speculative decoding, we’re essentially carpooling. Instead of making four separate trips to memory to fetch weights for four individual tokens, the model makes one trip and verifies a whole block of text. This drastically reduces the time-per-token, resulting in the fluid, lag-free generation we now expect from enterprise-grade assistants.
Benefits of Multi-Token Prediction
Let’s discuss the main advantages of implementing multi-token prediction.
Challenges and Limitations of Multi-Token Prediction
The tech world loves a silver bullet moment, and multi-token prediction (MTP) certainly arrived with that kind of fanfare. But, as anyone who has actually tried to push these architectures into production knows, the “free lunch” in AI usually comes with a hefty side of architectural heartburn.
Real-World Use Cases of Multi-Token Prediction
If the challenges of multi-token prediction (MTP) are the growing pains, the use cases are the victory lap. Here is where the predictive horizon actually meets the road.

AI coding assistants
Instead of trickling out code character by character, IDEs drop entire boilerplate endpoints into your editor instantly. By predicting logical sequences, the model anticipates return statements before you can catch carpal tunnel from pounding the Tab key.
Enterprise chatbots
Customer support bots, internal knowledge assistants, and sales copilots can respond faster while maintaining quality. MTP helps reduce waiting time in long conversations, especially when answers involve predictable structures such as summaries, FAQs, policy explanations, or step-by-step guidance.
Real-time apps and gaming
In live translation, MTP acts almost like a mind reader, guessing the end of a sentence while the speaker is still phrasing the beginning. This eliminates the awkward, uncanny-valley lag during international calls, while giving gaming NPCs (non-player characters) the fluid, stutter-free dialogue required for actual immersion.
On-device and edge AI
MTP’s real sleeper win is on your phone and wearables. Counterintuitively, firing up a local chip to burst out a four-token block hogs less battery than waking it up repeatedly for single syllables. It delivers fast, entirely offline summarization and smart replies without burning through your battery or leaking data to the cloud.
What Does SaM Solutions Offer?
Bringing high-performance architectures like multi-token prediction into production requires a mix of strategic insight and practical engineering, which is exactly where we come in.
At SaM Solutions, we guide you through the initial tech stack evaluation with our AI consulting services and develop highly responsive, low-latency applications tailored to your specific goals, whether that means deploying autonomous AI agents for complex planning, building fast AI chatbots to handle high-volume traffic, or leveraging our edge AI development services to squeeze maximum efficiency out of local hardware and edge devices.
To Wrap Up
Multi-token prediction changes the fundamental math of how machines communicate. By forcing LLMs to look at the horizon instead of the immediate next syllable, MTP finally aligns modern silicon with human logic. It’s the catalyst turning sluggish text-generators into fluid digital teammates. It is the new baseline for what production-grade AI looks like.
FAQ
Can multi-token prediction reduce cloud infrastructure costs?
Yes. By generating several tokens at once, multi-token prediction can reduce inference time and improve hardware utilization, which may lower compute and cloud serving costs for AI applications.
Does multi-token prediction work with small language models?
Which AI frameworks support multi-token prediction?
Can multi-token prediction improve code generation quality?













