Enterprise LLM Architecture: A Complete Guide


(If you prefer video content, please watch the concise video summary of this article below)
Key Facts
- Enterprise LLM architecture is less about picking a single “best” model and more about designing the surrounding stack: data, infrastructure, security, and integrations.
- A production-ready setup usually includes four layers: data processing and governance, model training and fine-tuning, deployment and serving infrastructure, and security with role-based access control.
- Choosing where to run your LLM (cloud, on-prem, or hybrid) depends on your compliance needs, speed, and budget.
- Retrieval-Augmented Generation (RAG) is becoming a standard pattern in enterprise LLMs, connecting models to vector databases and existing systems (CRM, ERP, CMS, intranet) so answers stay accurate, current, and grounded in company knowledge.
- Continuous monitoring of latency, throughput, token usage, error rates, and GPU load is essential to keep LLM solutions reliable and cost-effective.
- The next evolution of enterprise LLM architecture includes multimodal AI, autonomous agent systems, and advanced security protocols that embed zero-trust and regulatory requirements directly into the design.
Artificial intelligence has moved beyond pilot projects and experimental tools. Today, it transforms the way enterprises operate. Hence, the current question for enterprises is how to structure AI so that it delivers real business results.
It’s possible to say that large language models (LLMs) are the foundation of enterprise AI strategy, as they enable organizations to process unstructured data, automate knowledge-intensive tasks, and create new customer experiences.
Yet the real differentiator is not the model itself, but the architecture surrounding it. A well-designed enterprise LLM architecture determines whether an AI initiative becomes a cost-effective growth engine or stalls as a risky experiment.
This guide explores the fundamentals of LLM architecture for enterprises, its core components, deployment models, and future trends.
Leverage AI to transform your business with custom solutions from SaM Solutions’ expert developers.
What Is Enterprise LLM Architecture?
When enterprises deploy LLMs, they face challenges that go far beyond those of consumer-facing tools like chatbots or writing assistants. They need systems that can scale across departments, comply with regulations, and plug into critical business applications.
Enterprise LLM architecture is the structured framework that lets big companies use, manage, and scale large language models in a way that is safe, efficient, and in line with their business goals.
Unlike consumer applications of AI, enterprise-grade architecture must address unique requirements:
- Scalability to handle millions of transactions or documents across global operations.
- Compliance with sector-specific regulations such as GDPR, HIPAA, or financial reporting standards.
- Integration with existing IT investments, from ERP and CRM to data warehouses and analytics platforms.
- Cost control to ensure that AI implementation in your business drives ROI rather than uncontrolled infrastructure spending.
An LLM enterprise architecture acts as the bridge between cutting-edge AI capabilities and the operational realities of large organizations. It provides the technical backbone for innovation while keeping risks, costs, and compliance in check.
To understand why architecture matters, it helps to compare consumer-grade and enterprise-grade LLM systems.
| Dimension | Consumer LLMs | Enterprise LLMs |
| Scalability | Designed for individuals or small teams | Built to support global operations and large-scale data |
| Compliance | Minimal, general-purpose safeguards | Strict alignment with sector-specific regulations and industry norms |
| Integration | Standalone apps | Deep integration with ERP, CRM, and data warehouses |
| Security | Basic encryption and user authentication | Multi-layered security, zero-trust, role-based access |
| Customization | Limited personalization | Fine-tuned for sector-specific tasks and terminology |
| Cost management | Fixed subscription or usage fees | Flexible scaling, cost optimization for heavy workloads |
Core Components of Enterprise LLM Systems
An enterprise-ready large language model is a carefully layered system. It’s just like the anatomy of a living organism, where every layer performs a critical function that keeps the whole structure balanced, reliable, and secure.
Data processing and management layer
Data is the starting point and the key to success for every LLM project. Companies deal with huge amounts of data, such as sensor logs, medical reports, customer records, and financial documents. The data needs to be cleaned, annotated, and ingested before a model can work with it. Automated pipelines do things like getting rid of duplicates, normalizing formats, and tagging important entities.
Data governance is just as important. The GDPR in Europe and HIPAA in the United States are two examples of laws that set strict rules for how personal data can be stored and used. Without governance mechanisms, businesses risk not only bad model performance, but also fines from regulators and damage to their reputation. This is why mature enterprise AI infrastructure always has compliance monitoring at the data level.
Model training and fine-tuning
Once the data is ready, the next step is to shape the model itself. Businesses don’t often use off-the-shelf LLMs that haven’t been adjusted. Instead, they change models to fit their field by using a mix of training methods:
- Pre-training: starting from scratch with huge datasets (which is expensive and not common in businesses).
- Fine-tuning: changing existing models with data that is specific to a certain field, like legal documents for law firms.
- Instruction tuning: making models better at following specific task prompts.
Companies can choose between open-source frameworks (LLaMA, Falcon) and proprietary ones (GPT-4, Claude, Gemini). There are pros and cons to each choice when it comes to cost, openness, and reliance on the vendor. More and more, businesses are using synthetic data or reinforcement learning with human feedback (RLHF) to make things more accurate and cut down on the need for sensitive real-world datasets.
Deployment and serving infrastructure
An enterprise-grade LLM model is only useful if it can handle a lot of responses at once. The deployment layer gives you that backbone. Businesses depend on modern orchestration tools (Docker, Kubernetes) and serverless frameworks to host models in a reliable way.
Some of the problems in this layer are dealing with latency, scaling up when demand rises, and splitting up big models across several GPUs or nodes (model sharding). Low latency is very important for real-time situations like fraud detection or personalized recommendations. In some cases, edge computing is added to bring inference closer to the data source, which speeds up response times.
Security and access control
For businesses, security is not just nice to have; it’s a must-have. You need to protect sensitive prompts, results, and training data from being leaked or used inappropriately.
Only authorized users can access model APIs or dashboards thanks to strong role-based access control (RBAC). API keys and token management make integration points even safer, and end-to-end encryption keeps data safe while it’s being sent and when it’s not being sent.
Companies that have multi-tenant deployments, like SaaS vendors that serve many customers on the same system, must also make sure that data is kept completely separate. In this case, logical partitioning and containerization keep data from one client from ever getting into another client’s area.
Enterprise LLM Deployment Models
The way an organization deploys its LLMs is not just a technical choice. It shows strategic goals like following the rules, keeping costs down, and being able to grow quickly. Different industries and sizes of businesses need different approaches, and each model has its own pros and cons.
Implementing RAG for Enterprise LLMs
When businesses start using LLMs, they quickly run into a big problem: the model’s knowledge is only based on the data it was trained on and is limited on the cutoff date. If a business only uses a static model in markets that change quickly, it runs the risk of getting old information, hallucinated answers, and not being able to use company-specific knowledge. Retrieval Augmented Generation (RAG) fills this gap and is now a key part of modern LLM enterprise architecture.
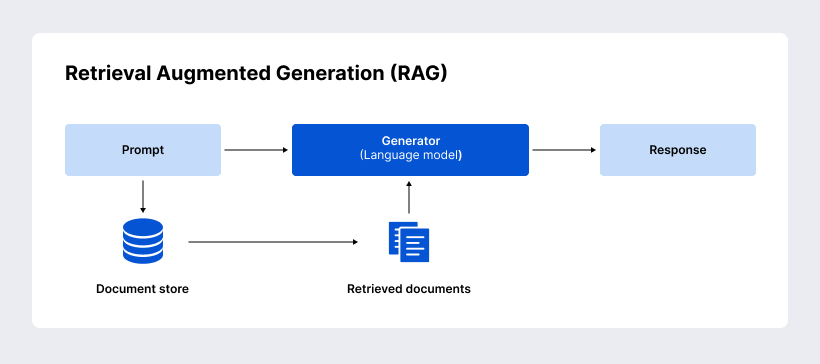
Retrieval augmented generation basics
RAG adds a retrieval step to the model pipeline to make it work. The LLM doesn’t just pull answers from memory; it also queries a knowledge base (like a document repository or intranet), finds the most relevant passages, and then uses this information to make an answer.
It’s clear what the benefits are:
- Higher accuracy and relevance, as the outputs are backed up by enterprise data.
- Reduced hallucination, as the model uses authoritative sources.
- Continuous adaptability, as updates to the knowledge base are immediately reflected in responses.
Vector databases and indexing
The vector database is the most important part of any RAG system. Such specialized databases, e.g., Pinecone, Weaviate, FAISS, and Qdrant, store text or documents as high-dimensional embeddings. This makes it possible to search for similar items very quickly.
For enterprises, this means being able to index vast knowledge bases: internal wikis, compliance manuals, product catalogs, or customer service logs. When a user asks a question, the database finds the most relevant documents and sends them to the LLM for generation that takes context into account.
It’s also important to have good indexing strategies. If the setup isn’t good, important documents might be missed. On the other hand, good indexing makes sure that all of the company’s knowledge assets are covered.
Integration with existing systems
When RAG connects directly to business workflows, it really shows its worth. This usually means connecting to:
- CRM systems (e.g., Salesforce) to show important customer interactions.
- ERP platforms (e.g., SAP) to help with HR, finance, or supply chain tasks.
- CMS and intranet portals for updates on policies or products in real time.
- Knowledge bases (e.g., Confluence or SharePoint) that can help employees find answers to their questions.
Such integrations are made possible by APIs, connectors, and embedding pipelines. This way, the model can get the most up-to-date and relevant information without having to build new infrastructure.
RAG business use cases
Enterprises are already using RAG in ways that have a direct effect on their profits:
- Customer support: Chatbots and AI agents for customer service can give you faster and more accurate answers by looking at product manuals and past tickets.
- Knowledge management: Employees can quickly get to important policies or technical documents, which cuts down on the time they spend looking through many systems.
- Decision intelligence: Executives and analysts use natural language to ask questions about company data so they can make faster, more informed decisions.
RAG changes static knowledge into a resource that is always available. This makes enterprise LLM architecture an active driver of operational efficiency and competitive advantage instead of a passive AI system.
Monitoring and Maintenance
Setting up an enterprise LLM is just the start. The real problem is making sure that the system works well, grows in a way that is good for the business environment, and stays within budget and legal limits. Ongoing monitoring and planned maintenance turn a promising pilot into a reliable business asset.
Performance tracking
Large language models can use a lot of resources, so businesses need to keep an eye on how well the system is working. Latency, throughput, and token usage are important numbers that have a direct effect on how users feel and how much it costs to run the system. A response that takes too long for customers can hurt trust, and for internal use cases, bottlenecks can make people less productive.
Modern observability stacks, such as Prometheus, Grafana, and OpenTelemetry, let teams see these metrics in real time. Businesses also track memory usage, error rates, and GPU load to figure out when they will need to scale up before it causes downtime. Tracking performance makes sure that an LLM deployment stays reliable and efficient, even as more people use it.
Model updates and versioning
Like any other software system, LLMs need to be updated. Changes to the model are often needed when new training data, bug fixes, or compliance changes are made. However, in enterprise environments, these updates must be done without causing any problems with business operations.
That’s why versioning strategies matter here. Enterprises often run several copies of the same model at the same time, with one handling production workloads and the other handling testing. Rollback mechanisms make sure that if a new version has bugs, systems can quickly go back to an older version without affecting users. In big companies, different departments may also have their own finely-tuned models, which means that the whole company needs to work together to govern them.
Cost optimization strategies
Running LLMs can be costly, especially when they get millions of queries a month. If you don’t plan ahead, infrastructure costs could get out of hand. To keep budgets predictable, businesses use a number of different strategies.
- Token budget management: limiting prompts that aren’t needed or making queries more efficient.
- Inference optimization: reducing idle costs by grouping requests or using serverless scaling.
- Model compression techniques: Quantization and distillation are two examples that lower memory and compute needs without hurting accuracy too much.
Organizations can get the most out of LLM enterprise architecture by using a combination of the above-mentioned strategies.
Future Trends in LLM Architecture
Enterprises are still in the early stages of using LLMs. As technology gets better, the way companies build and run their architectures will change quickly. Forward-thinking executives are already asking not just what can LLMs do today, but what role will they play in shaping tomorrow’s business ecosystems? And there are a few trends that stand out on the horizon.
Multimodal AI in the enterprise
Plain text alone is not often used for business communication. Contracts come with attachments, customer inquiries include screenshots, and industrial environments generate both sensor data and voice reports.
When businesses combine different types of data, they get a better overall picture of how their operations and customers work. So the next generation of enterprise LLM architecture will combine text, images, voice, and documents into one system.
A typical support platform will have an AI agent that reads a customer’s written complaint, checks a screenshot of an error, and listens to a short voice message before coming up with a clear, detailed answer.
For example, multimodal AI will be able to help manufacturers find risks sooner by looking at design blueprints and maintenance logs at the same time.
From assistants to autonomous agent systems
Today’s LLMs serve as assistants: answering queries, drafting text, or summarizing reports. The next step is to create autonomous agents that will plan strategies, carry out tasks, and learn from workflows.
These agents will not only give you information, but they will also do things like set up follow-up meetings, make changes to the supply chain, or organize multi-step compliance checks. Core elements will include:
- Workflow orchestration, where agents chain together multiple tasks automatically.
- Agent memory, allowing them to keep track of context between sessions and get better over time.
- Learning loops, where agents refine their strategies based on outcomes.
For businesses, this change means going from having people help with tasks to having some of them done automatically. This frees up employees to work on more important projects instead of doing the same things over and over.
Advanced security protocols
As LLMs become more important to business systems, security worries will grow. Businesses will need to use zero-trust architectures to make sure that every request is checked, no matter where it comes from. Data watermarking will help keep track of AI-generated content and hold people accountable. Red-teaming models will become standard practice to find weaknesses before enemies can take advantage of them.
Federated AI security is another step forward. It lets companies work together to train models and find risks without giving away raw data. This will be especially important in fields where sharing information can make things more stable, like when fighting cyberattacks or financial fraud.
On the regulatory side, the EU AI Act and similar frameworks worldwide will require enterprises to treat compliance as an integral part of their AI architecture, not an afterthought. Forward-looking organizations will design governance into their systems today to avoid costly retrofits tomorrow.
Why Choose SaM Solutions for AI Development?
Not every company needs the same AI solution, and not every problem should be solved with an LLM. At SaM Solutions, that’s our starting point. We bring together deep technical expertise and business sense to make sure your investment in AI translates into real-world results.
- Tailored consultation: We analyze your goals, data landscape, and compliance needs to identify the most suitable LLM model and architecture.
- Expert deployment: Our engineers specialize in building scalable, secure environments for LLMs, generative AI solutions, Retrieval-Augmented Generation (RAG), and AI agents.
- Secure integration: Data privacy is central to our approach. We design pipelines and retrieval systems that protect sensitive business and personal data while maximizing accuracy.
- Ongoing partnership: Beyond implementation, we provide continuous maintenance, index updates, and model tuning to keep your AI ecosystem current and effective.
- Practical guidance: We focus on value-driven use cases, advising when AI solutions make sense. If AI development is too costly or unlikely to deliver ROI, we’ll say so and suggest a more effective alternative. When the case is strong, we manage the full lifecycle, from design to deployment.
Wrapping Up
Large language models give businesses new opportunities. But success depends on more than just the model itself. A well-planned enterprise LLM architecture with strong data governance, safe deployment, and ongoing improvement is what makes AI useful for enterprises.
Retrieval-Augmented Generation (RAG), multimodal AI, and autonomous agents are some of the technologies that will shape the future. However, only companies with strong foundations will be able to use them to their full potential. People who make smart investments today will see long-term benefits in terms of efficiency, compliance, and innovation.
SaM Solutions helps businesses along the way, making sure that using AI has measurable effects and lasts for a long time.
FAQ
What is the typical cost range for implementing a bespoke enterprise LLM architecture?
Depending on the scope, infrastructure, and rules, the cost can be very different. A small-scale pilot that works with existing cloud services could start in the low six-figure range. Full-scale, custom enterprise deployments can cost millions of dollars.
Can a well-designed LLM architecture completely eliminate the risk of data leakage?
What are the key differences in architecting an LLM for customer service versus financial forecasting?













